
Authors:
(1) Nathan Lambert, Allen Institute for AI;
(2) Roberto Calandra, TU Dresden.
Table of Links
Understanding Objective Mismatch
Acknowledgments, and References
ABSTRACT
Reinforcement learning from human feedback (RLHF) has emerged as a powerful technique to make large language models (LLMs) easier to prompt and more capable in complex settings. RLHF at its core is providing a new toolkit to optimize LLMs other than next-token prediction, enabling the integration of qualitative training goals. The attempted match between user preferences and downstream performance, which happens in a learned reward model, results in an optimization landscape where training and evaluation metrics can appear correlated. The apparent correlation can lead to unexpected behaviors and stories of “too much RLHF.” In RLHF, challenges emerge because the following sub-modules are not consistent with each other: the reward model training, the policy model training, and the policy model evaluation. This mismatch results in models that sometimes avoid user requests through false safety flags, are difficult to steer to an intended characteristic, or always answer in a specific style. As chat model evaluation becomes increasingly nuanced, the reliance on a perceived link between reward model score and downstream performance drives the objective mismatch issue. In this paper, we illustrate the cause of this issue, reviewing relevant literature from model-based reinforcement learning, and discuss relevant solutions to encourage further research. By solving objective mismatch in RLHF, the LLMs of the future will be more precisely aligned to user instructions for both safety and helpfulness
1 Introduction
Reinforcement learning from human feedback (RLHF) is a powerful tool for integrating qualitative styles and values into large machine learning models (Bai et al., 2022; Christiano et al., 2017; Ouyang et al., 2022). RLHF was popularized with its use to integrated human values into large language models (LLMs) for aligning chat tools (Schulman, Zoph, Kim, & more, 2022). In doing so, RLHF has become an important technique in the process of making models better at responding to user requests, often referred to as instruction-tuned, steerability, chat-models, etc. RLHF methods typically operate in a two step process following the training of a base language model, first they learn a model of human preferences that acts as a reward function, and second they use this model within a reinforcement learning (RL) optimization loop. In the RLHF process, these two steps are often executed independently, with an accurate reward model being trained on human preference data and then the RL optimizer is used to extract maximum information into the chat model. A common challenge of modern LLMs trained with RLHF is difficulties in extracting intended behaviors from the model. Sometimes, the models decline benign requests for safety reasons and other times they need clever prompt tuning to extract full performance.
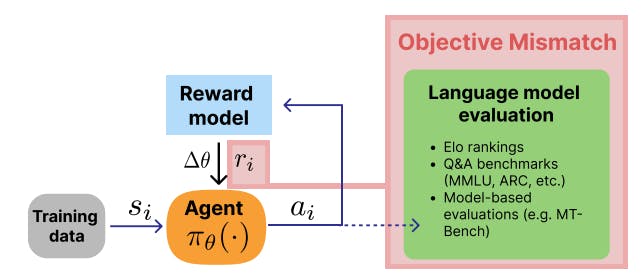
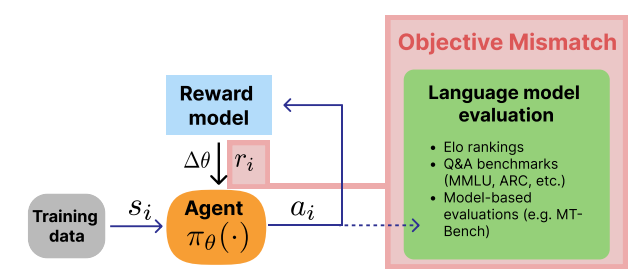
In this paper, we detail a fundamental challenge in modern RLHF learning schemes: the objective mismatch issue. In RLHF, three important parts of training are numerically decoupled: the design of evaluation metrics, the training of a reward model, and the training of the generating model. This mismatch between the reward model and the RL training is visualized in Fig. 1, yet other links exist between the goals of evaluation and simulating human values. Specifically, there are many avenues to better align reward model training to the literature in preference quantification (Lambert, Gilbert, & Zick, 2023) and fundamental optimization challenges need to be solved in RLHF practices (Casper et al., 2023). ChatGPT, the most popular model trained with RLHF, shows signs this limitation through issues such as verbosity, self-doubt and question refusals, repeated phrases, hedging, and more (Schulman, 2023). These traits of overoptimization are results of the subtle proxy objective problem that objective mismatch provides a frame for studying and solving – the reward model attributes excess value to phrases that do not contribute to user benefit, which the RL optimizer exploits, such as safety flags. On the hand, the current training setups are not fully aligned with evaluation tools because the RLHF’d models still need sophisticated prompting techniques such as “thinking step by step” (J. Wei et al., 2022) or “take a deep breath” (Yang et al., 2023) to reach maximum performance. Solving objective mismatch will remove the need for these advanced techniques and reduce the likelihood of out-of-scope refusals from an LLM.
The phrase objective mismatch originates from model-based reinforcement learning (MBRL), where an agent iteratively learns a dynamics model that it later uses to solve a control task (Lambert, Amos, Yadan, & Calandra, 2020; R. Wei, Lambert, McDonald, Garcia, & Calandra, 2023). In this context, the mismatch is between learning an accurate dynamics model rather than one that is optimized for high task reward. In RLHF, the problem is related, but with added complexity, as the reward model is optimized for preference data over a closed distribution, which does not match the end users. Second, the task of open-ended language generation is less specific to a notion of reward than that of RL control policies. For these reasons, as we explore in this paper, the objective mismatch issue is more nuanced and critical to RLHF.
In this position paper, we make three contributions:
• Clearly explain the origins and potential manifestations of objective mismatch in chat-tuned LLMs,
• Connect related work from NLP and RL literature around objective mismatch,
• Propose directions of study to solve the mismatch and foster better RLHF practices.
This paper is available on arxiv under CC 4.0 license.