
Authors:
(1) Tamay Aykut, Sureel, Palo Alto, California, USA;
(2) Markus Hofbauer, Technical University of Munich, Germany;
(3) Christopher Kuhn, Technical University of Munich, Germany;
(4) Eckehard Steinbach, Technical University of Munich, Germany;
(5) Bernd Girod, Stanford University, Stanford, California, USA.
Table of Links
Abstract
The COVID-19 pandemic shifted many events in our daily lives into the virtual domain. While virtual conference systems provide an alternative to physical meetings, larger events require a muted audience to avoid an accumulation of background noise and distorted audio. However, performing artists strongly rely on the feedback of their audience. We propose a concept for a virtual audience framework which supports all participants with the ambience of a real audience. Audience feedback is collected locally, allowing users to express enthusiasm or discontent by selecting means such as clapping, whistling, booing, and laughter. This feedback is sent as abstract information to a virtual audience server. We broadcast the combined virtual audience feedback information to all participants, which can be synthesized as a single acoustic feedback by the client. The synthesis can be done by turning the collective audience feedback into a prompt that is fed to state-of-the-art models such as AudioGen. This way, each user hears a single acoustic feedback sound of the entire virtual event, without requiring to unmute or risk hearing distorted, unsynchronized feedback.
Index Terms—Audio Synthesis, Multimedia Conference System, Virtual Audience
I. INTRODUCTION
Since COVID-19 first hit, many live performances moved to the virtual domain in addition to in-person events. While initially a necessary subpar substitute, virtual events are now a unique new opportunity for performing artists such as comedians, actors, and musicians. However, performing such events without instantaneous feedback is challenging and not comparable with on-site shows. The audience in larger online meeting needs to be muted to avoid disturbing background noise. Interactive audience feedback such as applause or laughter is therefore not possible.
So far, virtual conference systems do not offer the functionality to share acoustic audience feedback across the session. Feedback by multiple participants at once is currently restricted to using text chat or signs such as hand waving. This lack of audience interaction poses a significant challenge for performing artists who report that Zoom shows cannot replace in-person performances [1]. It has been shown that integrating laughter into virtual meetings significantly improves the social experience of the participants [2]. Without collective feedback of the audience such as laughter, a core part of human interaction in large events is missing.
Integrating acoustic audience feedback into an online conference faces several challenges. Due to network lag, different feedback sounds need to be synchronized and normalized before playing them. Raw audio data from many participants containing feedback such as laughter contains accumulating background noise. An alternative to transmitting raw audio data is to synthesize it. While the field of audio synthesis is mostly focused on speech synthesis [3], [4], [5], nonverbal audio sounds such as laughter can be synthesized as well [6], [7]. More recently, Meta’s Audiocraft [8] further increased the capabilities of audio generation based on abstract information in the form of text prompts.
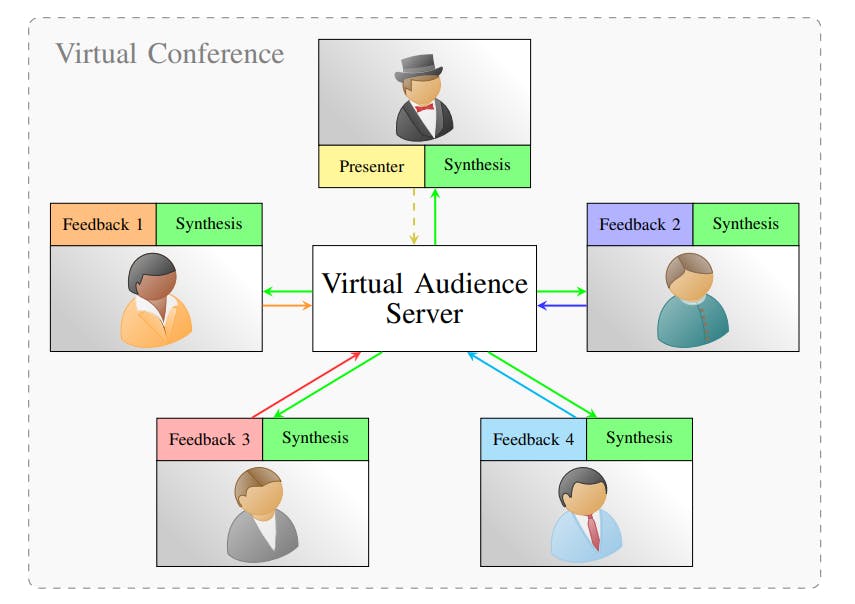
In this paper, we propose to leverage recent advances in audio synthesis of acoustic audience feedback to integrate collective audience sound into virtual events. In contrast to speech, information about the audience feedback such as laughter or clapping can be compressed efficiently into abstract state information. We propose a virtual audience framework that allows audience interaction without the transmission of the actual audio information. The concept of the proposed framework is shown in Figure 1.
On the client input side, every participant shares abstract information about their reactions which we merge at a central virtual audience server. We then use the abstract feedback state to synthesize a single joint audience sound, for example by turning the feedback state into a prompt and using text-tosound generative models to obtain the audio. The joint audio sound is then sent back to each user, allowing each user to hear the feedback of the entire audience without overlays or distortion. By continuously updating the feedback state, the audio played for each user can be updated repeatedly to enable an audience sound that fits the current events.
The rest of this paper is organized as follows. Section II summarizes related work in the field of audience audio synthesis. We propose a joint acoustic audience framework for large virtual events in Section III. Then, we present a potential implementation of synthesizing joint audio sounds using stateof-the-art generative AI. Section IV concludes the paper.
This paper is available on arxiv under CC 4.0 license.