
Authors:
(1) Tamay Aykut, Sureel, Palo Alto, California, USA;
(2) Markus Hofbauer, Technical University of Munich, Germany;
(3) Christopher Kuhn, Technical University of Munich, Germany;
(4) Eckehard Steinbach, Technical University of Munich, Germany;
(5) Bernd Girod, Stanford University, Stanford, California, USA.
Table of Links
III. VIRTUAL AUDIENCE FRAMEWORK
In this section, we present the proposed virtual audience framework. We focus on online events where a single client provides the content for all other participants in the session. This single presenting client interacts with the audience based on their reactions and uses this as feedback for their future behavior. Such feedback is especially relevant for performing artists that rely on live shows.
A. Concept
In the scenario we focus on, the presenter depends on the reaction of the entire audience rather than detailed feedback by individuals. In case of multiple participants talking or the entire audience sending feedback at the same time, noise can accumulate and drown out valuable feedback. To avoid accumulating noise, the audio of multiple participants in an online meeting typically needs to be synchronized. Since nonverbal acoustic feedback information such as clapping, whistling, booing, and laughter is less complex than speech, we propose to avoid requiring complex synchronization schemes. We only require an abstract representation of the current audience state denoting which participant is actively clapping, whistling, booing, and laughter. This abstract audience state can then be shared with all participants. The acoustic feedback can then be synthesized locally from the received audience state. This way, each participant can be played the overall acoustic feedback without having to synchronize raw audio.
B. Implementation
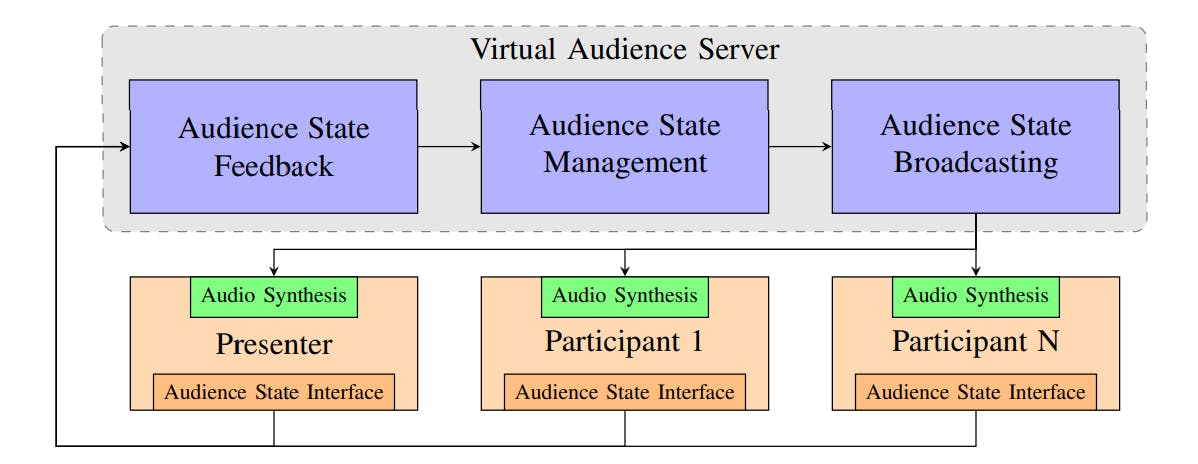
To implement the proposed concept, we share the abstract audience state information with all participants via a central server. We define the audience state as a vector of binary variables for each participant, with each variable representing whether the user is exhibiting a particular reaction. Whenever a client changes their reaction state, the updated state information is sent to the central virtual audience server. The central virtual audience server merges all information and broadcasts the updated current audience state information to every client. Finally, every client synthesises the audience feedback locally for the current audience state. The transmission of such abstract state information results in an additional transmission rate of a few bytes which is fundamentally less compared to the transmission of an audio or video stream. Figure 2 summarizes the concept for the virtual audience framework.
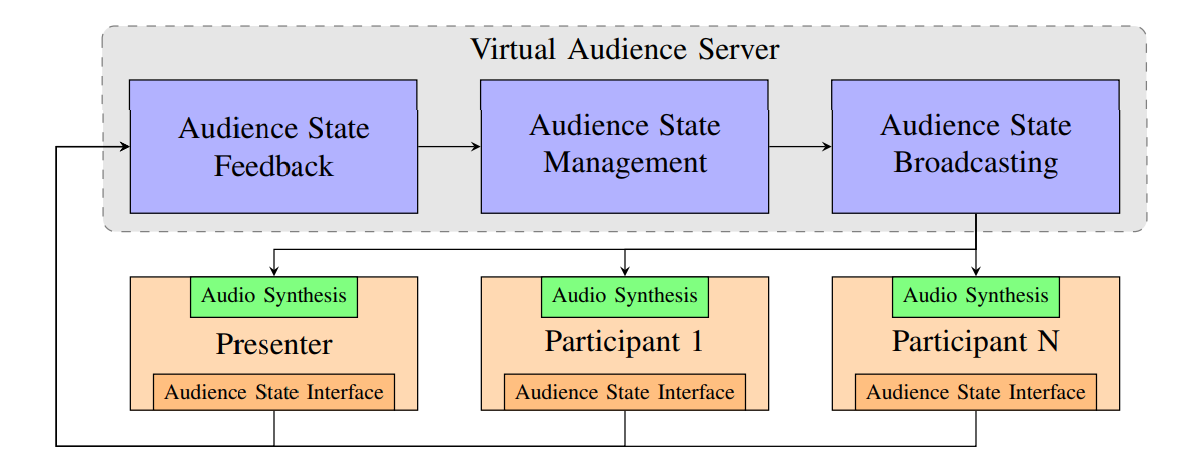
On the client side, we define an input interface that collects the abstract state information from the users and an output interface that converts the current audience state information into an audio stream. For synthesizing the audio, any state-ofthe-art technique such as AudioGen [8] or MusicGen [26] can be used.
The input interface enables a flexible implementation due to the simplicity of the abstract state information that will be transmitted to the virtual audience server. A Graphical User Interface (GUI) is a simple way for allowing audience contributions. Similar to hand waving in Zoom, participants can share feedback via their GUI. This feedback is collected on the sever and the resulting audience state will be synthesized on every client into an acoustic audience signal. We obtain the abstract state information from the clapping, whistling, booing, and laughter of the user using a GUI or detection methods such as [34]. The transmission of the abstract state information instead of the actual audio signal avoids audio synchronization issues and comes with a negligible transmission overhead as small as a few bytes.
This paper is available on arxiv under CC 4.0 license.